
目次
邪馬台国探索のためのデータの描画
本を読んでフィーリングで大和と書いてある場所を邪馬台国と比定しますか?もちろんその方法は間違いです。神社でお参りして神がかって邪馬台国の場所のお告げをもらいますか?もちろん不可能です。
では、鏡や鉄鏃の分布を描画してみて関係性をグラフに出して邪馬台国の場所を説明しようと思いますか?これは正しい科学的なアプローチの第一歩です。この講座では最終的に安本先生の統計的手法やデータサイエンス的手法を再現することを目的としています。
Pythonでのプロット
PythonはMatplotlibやSeabornなどの豊富なライブラリを備えており、多様なプロットを作成できる環境を提供します。ここでは、PythonのMatplotlibを用いた幅広い可視化手法を学びます。
基本的な折れ線グラフから、ヒストグラム、箱ひげ図、ヒートマップのようなより複雑な可視化まで、さまざまなプロットの作成とカスタマイズ方法を扱います。データ可視化はデータサイエンスの中核です。これらのプロット技術を身につけることで、データの探索、傾向の把握、そして分析結果の効果的な伝達が可能になります。
データサイエンスの学習を進めるにつれて、これらのスキルはデータを実行可能な洞察へ変換するうえで大いに役立ちます。
基本プロット
Matplotlibの導入
MatplotlibはPythonでもっとも広く使われているプロットライブラリです。静的・アニメーション・インタラクティブといった多様なプロットを作成できる柔軟な基盤を提供します。個別のプロット種類に入る前に、Matplotlibの基本を確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # サンプルデータ x = [1, 2, 3, 4, 5] y = [10, 15, 20, 25, 30] # 基本的な折れ線プロット plt.plot(x, y) # タイトルとラベルを追加する plt.title('Basic Line Plot') plt.xlabel('X-axis Label') plt.ylabel('Y-axis Label') # プロットを保存する plt.plot() fig.savefig('plots/introduction.png') |
このコードは、軸ラベルとタイトルを付けた単純な折れ線グラフを作成します。この基本構造は、Matplotlibのさまざまなプロットに共通します。
折れ線グラフ(Line Plot)
折れ線グラフは時系列データの可視化でよく使われ、一定期間にわたる傾向を示すのに有用です。より詳細な例として、数年にわたる企業の年間売上(収益)推移を追跡します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:年と売上(百万ドル) years = [2018, 2019, 2020, 2021, 2022] revenue = [50, 55, 60, 68, 75] # 折れ線グラフを作成する plt.plot(years, revenue, marker='o', linestyle='-', color='blue') # グリッドを追加する plt.grid(True) # タイトルとラベルを追加する plt.title('Company Revenue Over Years') plt.xlabel('Year') plt.ylabel('Revenue (in million dollars)') # 特定ポイントに注釈を付ける plt.text(2019, 55, 'Dip in Growth', fontsize=12, color='red') plt.text(2022, 75, 'Record High', fontsize=12, color='green') # プロットを保存する plt.plot() fig.savefig('plots/line.png') |
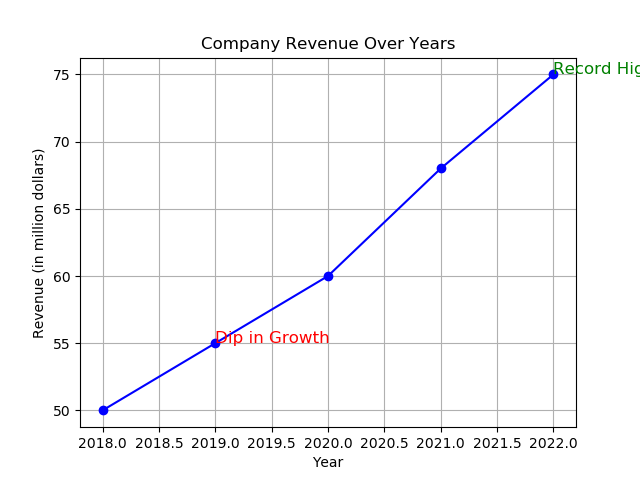
この折れ線グラフでは、各データ点にマーカーを付け、見やすさのためにグリッドを追加し、注目点に注釈を付けます。これにより、より明確で情報量の多い可視化になります。
散布図(Scatter Plot)
散布図は2つの変数の関係を理解するために不可欠です。相関、クラスタ、外れ値を見つけるのに役立ちます。ここでは広告費と売上の関係を調べる散布図を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:広告予算と売上 ad_budget = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] revenue = [15, 25, 35, 45, 50, 60, 65, 70, 80, 90] # 散布図を作成する plt.scatter(ad_budget, revenue, color='purple', alpha=0.5) # プロットを調整する plt.title('Advertising Budget vs Revenue') plt.xlabel('Advertising Budget (in thousand dollars)') plt.ylabel('Revenue (in thousand dollars)') # トレンドラインを追加する import numpy as np z = np.polyfit(ad_budget, revenue, 1) p = np.poly1d(z) plt.plot(ad_budget, p(ad_budget), "r--") # プロットを保存する plt.plot() fig.savefig('plots/scatter.png') |
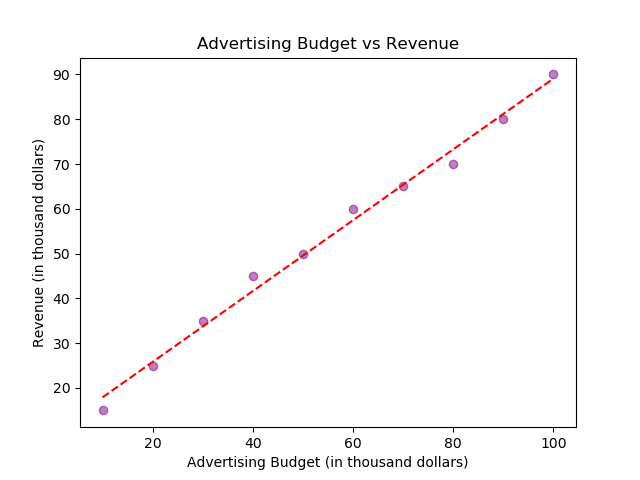
この散布図は、広告費と売上の間に正の相関があることを示します。トレンドラインを追加することで、この関係がより分かりやすくなります。
散布図のカスタマイズ
散布図はさまざまな方法でカスタマイズでき、より情報量の多い図にできます。点の大きさを変えたり、カテゴリによって色を変えたり、点にラベルを付けたりできます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import matplotlib.pyplot as plt import numpy as np # Figureオブジェクト fig = plt.figure() # データ:広告予算、売上、地域 ad_budget = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] revenue = [15, 25, 35, 45, 50, 60, 65, 70, 80, 90] regions = ['North', 'South', 'East', 'West', 'North', 'South', 'East', 'West', 'North', 'South'] sizes = np.array([100, 200, 300, 400, 100, 200, 300, 400, 100, 200]) # 地域を色に対応付ける color_map = {'North': 'blue', 'South': 'green', 'East': 'red', 'West': 'orange'} colors = [color_map[region] for region in regions] # 散布図を作成する plt.scatter(ad_budget, revenue, s=sizes, c=colors, alpha=0.6, edgecolor='black', linewidth=1.5) # プロットを調整する plt.title('Advertising Budget vs Revenue by Region') plt.xlabel('Advertising Budget (in thousand dollars)') plt.ylabel('Revenue (in thousand dollars)') # トレンドラインを追加する z = np.polyfit(ad_budget, revenue, 1) p = np.poly1d(z) plt.plot(ad_budget, p(ad_budget), "r--") # 凡例を追加する plt.legend(handles=[plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='blue', markersize=10, label='North'), plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='green', markersize=10, label='South'), plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='red', markersize=10, label='East'), plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='orange', markersize=10, label='West')]) # プロットを保存する plt.plot() fig.savefig('plots/custom_scatter.png') |
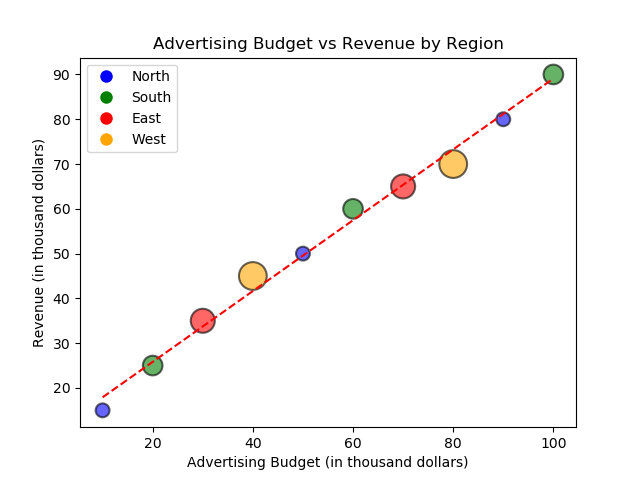
この補足した散布図は、広告予算と売上の関係を示すだけでなく、地域ごとにデータを区分し、トレンドラインも追加します。点の大きさは各データ点の相対的な重要度や規模を表し、さらに情報の層を加えます。
ヒストグラム、棒グラフ、円グラフ、箱ひげ図
ヒストグラム(Histogram)
ヒストグラムはデータ分布を可視化する強力な手法です。ある範囲(ビン)ごとに値の頻度を示すため、データがどのように分布しているかを理解するのに役立ちます。ここでは、小売店の顧客年齢の分布を分析するヒストグラムを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import matplotlib.pyplot as plt import numpy as np # Figureオブジェクト fig = plt.figure() # データ:顧客の年齢 ages = [18, 20, 22, 25, 28, 30, 35, 38, 40, 45, 48, 50, 55, 58, 60, 62, 65, 68, 70, 72, 75, 78, 80] # ヒストグラムを作成する(ビンと色を指定する) plt.hist(ages, bins=8, color='skyblue', edgecolor='black') # プロットを調整する plt.title('Age Distribution of Customers') plt.xlabel('Age') plt.ylabel('Number of Customers') # 平均年齢の縦線を追加する mean_age = np.mean(ages) plt.axvline(mean_age, color='red', linestyle='dashed', linewidth=1) plt.text(mean_age + 1, 5, 'Mean Age: {:.2f}'.format(mean_age), color='red') # プロットを保存する plt.plot() fig.savefig('plots/histogram.png') |
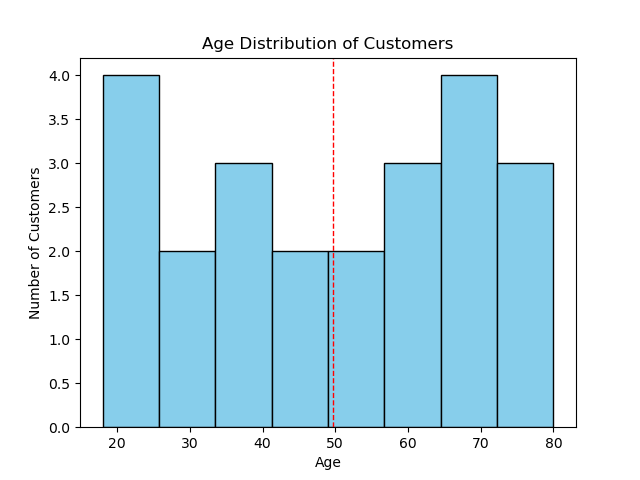
このヒストグラムは顧客年齢の分布を示し、縦線で平均年齢を示します。これは顧客の年齢層を理解するのに有用です。
ヒストグラムで分布を比較する
ヒストグラムは、異なるグループ間で分布を比較する場合にも便利です。ここでは、2つの店舗の顧客年齢分布を比較します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:2店舗の顧客年齢 ages_store1 = [18, 22, 25, 28, 30, 35, 38, 40, 45, 50, 55, 60, 65, 70, 75, 80] ages_store2 = [20, 23, 27, 30, 32, 37, 40, 42, 47, 52, 58, 63, 68, 72, 72, 72] # 重ね合わせたヒストグラムを作成する plt.hist(ages_store1, bins=8, alpha=0.5, label='Store 1', color='blue', edgecolor='black') plt.hist(ages_store2, bins=8, alpha=0.5, label='Store 2', color='green', edgecolor='black') # プロットを調整する plt.title('Age Distribution of Customers by Store') plt.xlabel('Age') plt.ylabel('Number of Customers') # 凡例を追加する plt.legend() # プロットを保存する plt.plot() fig.savefig('plots/distributions_with_histograms.png') |
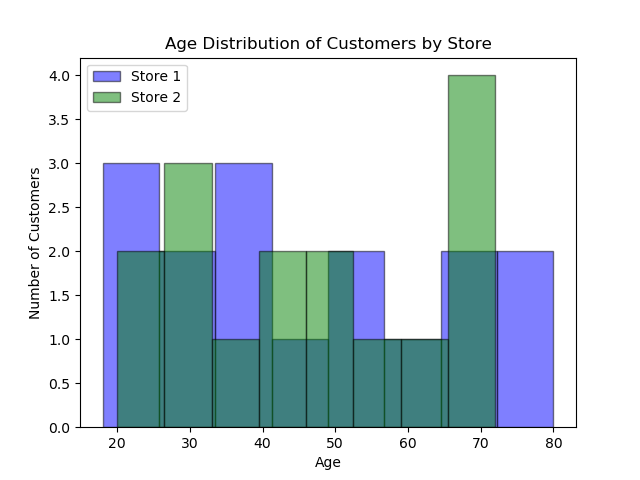
このヒストグラムは2店舗の年齢分布を比較し、顧客層の違いを見つけるのに役立ちます。
棒グラフ(Bar Plot)
棒グラフはカテゴリ間の数量比較に有効です。ここでは、製品ごとの平均売上を比較する棒グラフを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:製品と平均売上(千ドル) products = ['Product A', 'Product B', 'Product C', 'Product D'] avg_revenue = [20, 34, 30, 35] # 棒グラフを作成する plt.bar(products, avg_revenue, color='purple', edgecolor='black') # プロットを調整する plt.title('Average Revenue by Product') plt.xlabel('Product') plt.ylabel('Average Revenue (in thousand dollars)') # 棒の上に値を表示する for i, v in enumerate(avg_revenue): plt.text(i, v + 0.5, str(v), ha='center', color='black', fontsize=12) # プロットを保存する plt.plot() fig.savefig('plots/bar.png') |
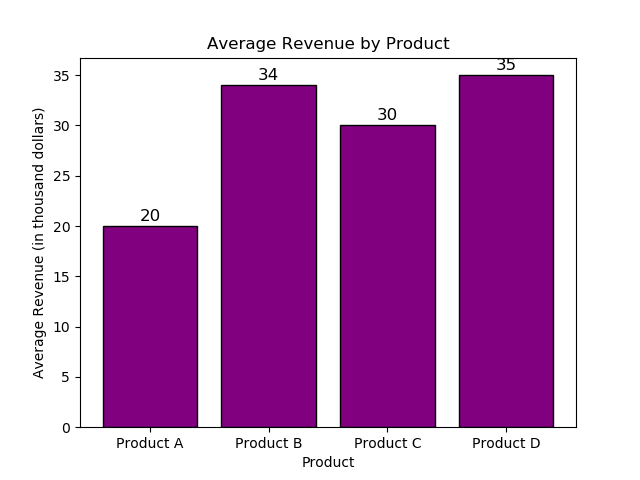
この棒グラフは製品間の売上の違いを示し、棒の上に値を表示して見やすくします。
グループ化棒グラフ(Grouped Bar Plot)
グループ化棒グラフは、各カテゴリについて複数グループを比較したい場合に便利です。ここでは、2つの地域における製品別売上を比較します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import matplotlib.pyplot as plt import numpy as np # Figureオブジェクト fig = plt.figure() # データ:製品と2地域の売上 products = ['Product A', 'Product B', 'Product C', 'Product D'] revenue_region1 = [20, 34, 30, 35] revenue_region2 = [25, 32, 34, 40] # 棒の位置用のインデックスを作成する index = np.arange(len(products)) bar_width = 0.35 # 棒グラフを作成する plt.bar(index, revenue_region1, bar_width, label='Region 1', color='blue', edgecolor='black') plt.bar(index + bar_width, revenue_region2, bar_width, label='Region 2', color='green', edgecolor='black') # プロットを調整する plt.title('Revenue by Product and Region') plt.xlabel('Product') plt.ylabel('Revenue (in thousand dollars)') plt.xticks(index + bar_width / 2, products) plt.legend() # プロットを保存する plt.plot() fig.savefig('plots/grouped_bar.png') |
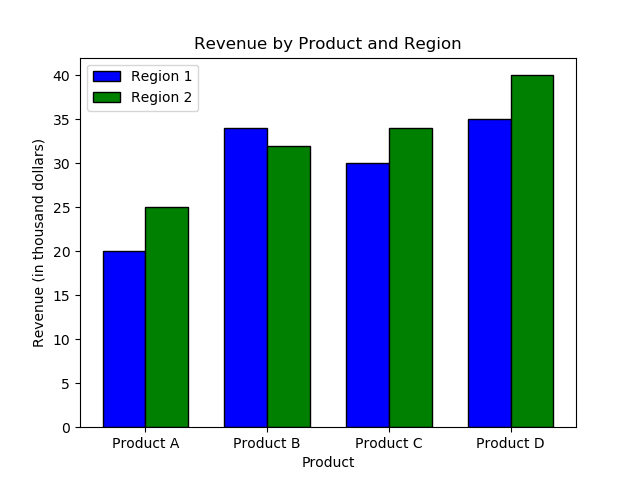
このグループ化棒グラフは、各製品について2地域の売上を比較でき、カテゴリ内とカテゴリ間の比較を容易にします。
円グラフ(Pie Chart)
円グラフは、全体に占める割合を示すのに適しています。ここでは、ある業界における企業の市場シェアを円グラフで表します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:企業の市場シェア companies = ['Company A', 'Company B', 'Company C', 'Company D'] market_share = [35, 30, 25, 10] # 円グラフを作成する plt.pie(market_share, labels=companies, autopct='%1.1f%%', startangle=140, colors=['gold', 'lightblue', 'lightgreen', 'lightcoral']) # プロットを調整する plt.title('Market Share of Companies') # 3D効果のために影を追加する plt.pie(market_share, labels=companies, autopct='%1.1f%%', startangle=140, colors=['gold', 'lightblue', 'lightgreen', 'lightcoral'], shadow=True) # プロットを保存する plt.plot() fig.savefig('plots/pie.png') |
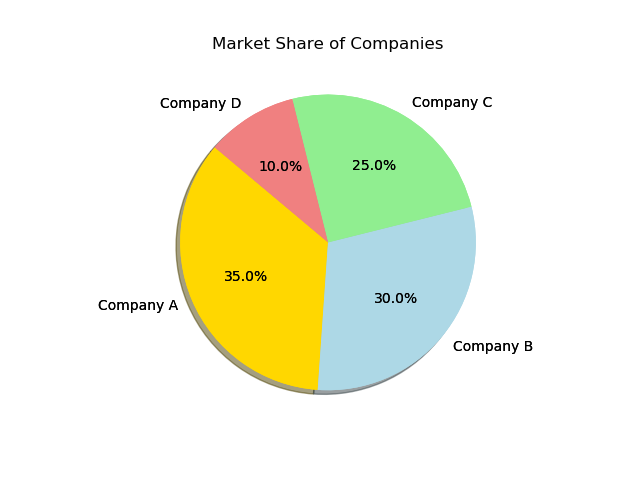
この円グラフは企業ごとの市場シェアの割合を示します。色分けや影の効果により、見た目も分かりやすくなります。
箱ひげ図(Box Plot)
箱ひげ図は、データの広がりや偏りを可視化し、外れ値も示せるため有用です。ここでは、店舗の1か月分の日次売上の分布を箱ひげ図で分析します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import matplotlib.pyplot as plt import numpy as np # Figureオブジェクト fig = plt.figure() # データ:1か月の日次売上(ドル) daily_sales = [220, 240, 250, 300, 310, 330, 350, 360, 370, 400, 410, 430, 440, 450, 460, 480, 490, 500, 520, 540, 550, 560, 580, 590, 600, 610, 620, 630, 640, 650] # 箱ひげ図を作成する plt.boxplot(daily_sales, vert=False, patch_artist=True, notch=True, boxprops=dict(facecolor='lightblue')) # プロットを調整する plt.title('Distribution of Daily Sales') plt.xlabel('Sales (in dollars)') # 平均を強調する plt.axvline(np.mean(daily_sales), color='red', linestyle='dashed', linewidth=1) plt.text(np.mean(daily_sales) + 10, 1.1, 'Mean', color='red') # プロットを保存する plt.plot() fig.savefig('plots/box.png') |
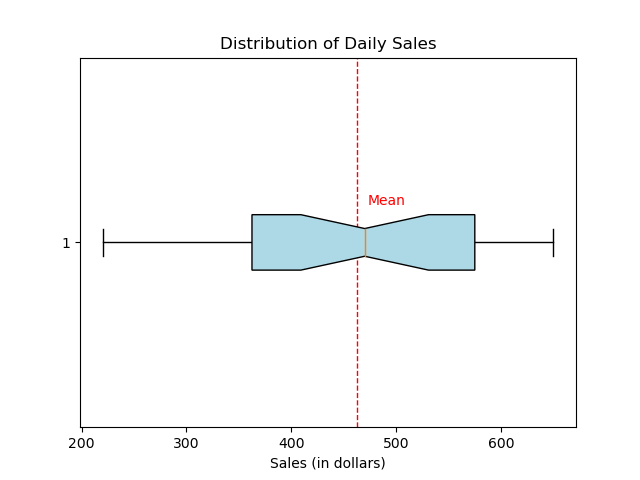
箱ひげ図は、中央値、四分位、外れ値候補を示し、日次売上の分布を要約します。ノッチは中央値の信頼区間を表し、破線は平均を強調します。
複数の箱ひげ図
複数の箱ひげ図を使うと、カテゴリごとの分布比較ができます。ここでは、複数店舗のロケーション別に日次売上を比較します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import matplotlib.pyplot as plt # Figureオブジェクト fig = plt.figure() # データ:店舗ロケーション別の日次売上 sales_location1 = [220, 240, 250, 300, 310, 330, 350, 360, 370, 400] sales_location2 = [410, 430, 440, 450, 460, 480, 490, 500, 520, 540] sales_location3 = [550, 560, 580, 590, 600, 610, 620, 630, 640, 650] # データをリストにまとめる sales_data = [sales_location1, sales_location2, sales_location3] # ロケーションごとの箱ひげ図を作成する plt.boxplot(sales_data, patch_artist=True, notch=True, boxprops=dict(facecolor='lightgreen')) # プロットを調整する plt.title('Comparison of Daily Sales Across Store Locations') plt.xlabel('Store Location') plt.ylabel('Sales (in dollars)') plt.xticks([1, 2, 3], ['Location 1', 'Location 2', 'Location 3']) # プロットを保存する plt.plot() fig.savefig('plots/multi_box.png') |
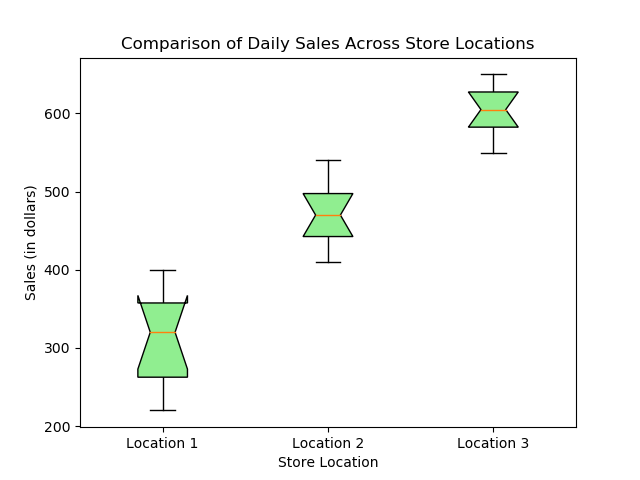
このプロットは、店舗ロケーション間で売上分布を比較し、中央値やばらつき、外れ値候補の違いを把握しやすくします。
3Dサーフェスプロット
3Dサーフェスプロットは、3次元データを表現するグラフです。2つの変数(XとY)の値を水平・垂直の軸に取り、3つ目の変数(Z)を面の高さや色として表します。このプロットは、ZがXとYの関数としてどのように変化するかを示し、X-Y平面上に連続した面を作ります。3変数間の複雑な関係を可視化するのに特に有用であり、数学関数、科学データ、その他の多次元データセットの探索に使えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
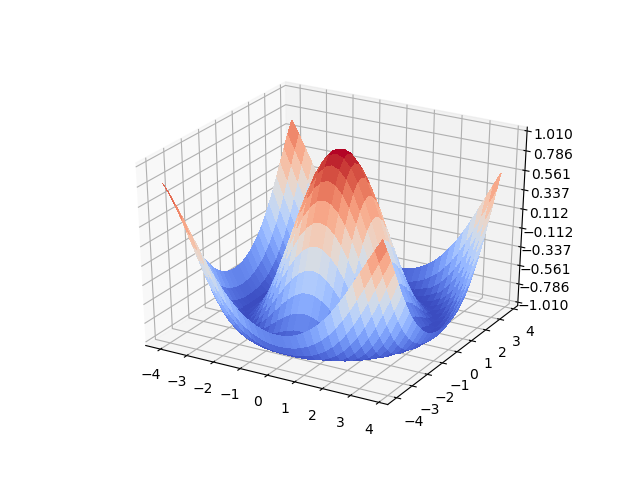
import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D # 3Dプロットを有効にするためにインポートする from matplotlib import cm from matplotlib.ticker import LinearLocator import numpy as np # Figureと3D軸を作成する fig, ax = plt.subplots(subplot_kw={"projection": "3d"}) # データを作成する X = np.arange(-4, 4, 0.25) Y = np.arange(-4, 4, 0.25) X, Y = np.meshgrid(X, Y) R = np.sqrt(X**2 + Y**2) Z = np.cos(R) # 面を描画する surf = ax.plot_surface(X, Y, Z, cmap=cm.coolwarm, linewidth=0, antialiased=False) # Z軸を調整する ax.set_zlim(-1.01, 1.01) ax.zaxis.set_major_locator(LinearLocator(10)) #ax.zaxis.set_major_formatter('{x:.02f}') # 値と色を対応付けるカラーバーを追加する #fig.colorbar(surf, shrink=0.5, aspect=5) # PNGファイルとして保存する plt.savefig("plots/3D_surface_plot.png") |
このコードでは、MatplotlibとNumPyを使って3Dサーフェスプロットを作成します。XとYの格子点を生成し、原点からの距離に対するコサインとしてZを計算し、滑らかで波のような外観を持つ色付きの面として可視化します。
ヒートマップ
ヒートマップは、行列形式でデータを表示し、値を色の強さで表現する強力な可視化手法です。相関関係を示したり、大規模データを視覚化したりするのに特に有用です。ここでは、データセット内の変数間の相関を可視化するヒートマップを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import matplotlib.pyplot as plt import seaborn as sns import numpy as np # Figureオブジェクト fig = plt.figure() # データ:相関行列 data = np.random.rand(10, 10) corr_matrix = np.corrcoef(data) # ヒートマップを作成する sns.heatmap(corr_matrix, annot=True, cmap='coolwarm') # プロットを調整する plt.title('Correlation Heatmap') # プロットを保存する plt.plot() fig.savefig('plots/heatmap.png', transparent=True) |
このヒートマップは相関行列を表示し、各セルの色が2変数間の相関の強さを表します。注釈として表示される数値は相関係数を示し、相関の程度を正確に把握できます。
まとめ
ここではまず邪馬台国データサイエンティストが知っているべき描画機能の初歩を説明しました。この連載はまだまだ続きます。