
目次
はじめに
邪馬台国を探すためには文章や地名を読めばそこに答えが書いてあるのだろうか?もちろん答えなどどこにも書いてありません。それ故に万人はその発見に失敗している。千年以上前の文章を読み、西にあはぎ原があれば西へ行き、東に高千穂があれば東へ行き、北にオノコロ島があれば北海道へも飛ぶ。南を北と言い換えて奈良に旅し、洞窟があればそれを天の岩戸と呼ぶ。
つまり、過去に万人が行ったアプローチとは違う21世紀の強力な武器を使いこなす必要があります。
それは神のツール、
- データ
- コンピュータ
- 最新の技術
です。ここで紹介するのは強力な現代のツールであり大御神、データサイエンスです。この講座は長期連載し、最終的に安本美典氏の統計的手法・データサイエンス的手法を読者が再現できるようになる所で終了する予定です。
元々は個人の趣味で書いていた「Data Scientist - A Beginner's Guide to Mastering Data Science, Gen K. Mariendorf」が基礎になっています。第一章は邪馬台国を探求する皆が愛して止まないであろうPythonの基礎の基礎です。

Pythonの基礎
Pythonの基礎へようこそ。ここでは、Pythonの学習を始めたばかりのデータサイエンティスト志望者に向けて、導入となる内容を扱います。
この章では、Pythonのモジュールとクラス、基本的な演算、条件分岐、そしてループ処理を扱います。モジュールとクラスは、プログラムを構造化し、再利用性を高め、オブジェクト指向の考え方を実装するための重要な構成要素です。また、Pythonの概念と基本構文はあらゆるPythonプログラムの土台となり、計算を行い、意思決定をし、処理を効率よく繰り返すことを可能にします。データ分析、モデル構築、あるいはタスクの自動化など、目的が何であっても、これらの基礎スキルは次のステップへ進むための足がかりになります。
Pythonのモジュールとクラス
モジュールとクラスは、コードを整理し、構造化し、再利用するための強力な道具です。モジュールはコードを部品化して管理しやすくし、クラスはオブジェクト指向プログラミングを可能にして、より柔軟で拡張しやすいコードを実現します。
Pythonのモジュール
Pythonにおけるモジュールは、関数や変数、あるいは他のクラスなど、Pythonの定義や文を含むファイルです。モジュールを使うとコードを再利用可能な部品として整理でき、プロジェクトの保守や拡張がしやすくなります。モジュールは、コード内で使える関数やクラスをまとめたライブラリやツールキットのようなものだと考えられます。Pythonには大きな標準ライブラリがあり、自分でモジュールを作成することもできます。
モジュールのインポート
モジュールは通常、importキーワードを使ってPythonスクリプトに取り込みます。たとえば、数学関数を使うためにmathモジュールをインポートする例を示します。
|
1 2 3 4 5 6 7 8 |
# mathモジュールのインポート import math # mathモジュールの関数を使用する result = math.sqrt(25) print(result) # 出力: 5.0 |
出力:
|
1 2 3 |
5.0 |
この例では、組み込みのmathモジュールをインポートし、数の平方根を計算するsqrt()関数を利用します。
自作モジュールの作成とインポート
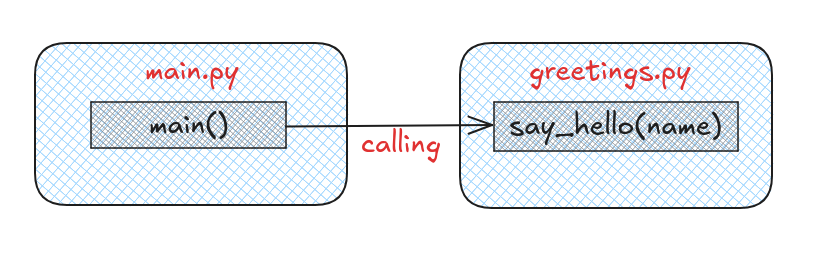
.py拡張子のPythonファイルとして保存すれば、自分専用のモジュールを作成でき、他のファイルからインポートして利用できます。たとえば、greetings.pyというファイルがあるとします。
|
1 2 3 4 5 |
# greetings.py def say_hello(name): return f"Hello, {name}!" |
このモジュールを別のPythonスクリプトでインポートして使うには、次のようにします。
|
1 2 3 4 5 6 7 |
# main.py import greetings message = greetings.say_hello("Alice") print(message) # 出力: Hello, Alice! |
出力:
|
1 2 3 |
Hello, Alice! |
このようにすることで、コードを別ファイルに分けて整理し、複数のプロジェクトで再利用できるようになります。
Pythonのクラス
クラスは、Pythonでオブジェクト(インスタンス)を作成するための設計図です。クラスは、データと、そのデータに関連する振る舞い(関数やメソッド)をひとまとめにします。クラスを使うことで、継承、カプセル化、多態性といったオブジェクト指向プログラミング(OOP)の考え方を実装できます。
クラスの定義
Pythonでクラスを定義するには、classキーワードの後にクラス名を書きます。クラスには属性(変数)やメソッド(関数)を含められます。次に簡単な例を示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Dogというクラスを定義する class Dog: # 属性を初期化するためのコンストラクタメソッド def __init__(self, name, breed): self.name = name # 属性 self.breed = breed # 属性 # 犬の情報を表示するメソッド def display_info(self): return f"{self.name} is a {self.breed}" # Dogクラスのオブジェクトを作成する dog1 = Dog("Buddy", "Golden Retriever") print(dog1.display_info()) # 出力: Buddy is a Golden Retriever |
出力:
|
1 2 3 |
Buddy is a Golden Retriever |
Dogクラスを定義し、nameとbreedという2つの属性を持たせます。__init__メソッドはクラスのコンストラクタであり、オブジェクト作成時に属性を初期化します。display_info()メソッドを追加し、犬を説明する文字列を返します。
複数インスタンスの作成
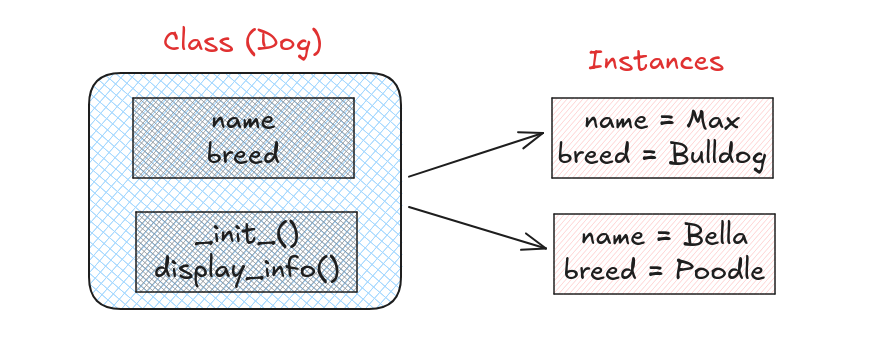
クラスの主な利点のひとつは、異なるデータを持つ複数のインスタンス(オブジェクト)を作成できる点にあります。
|
1 2 3 4 5 6 7 8 |
# Dogクラスのオブジェクトを2つ作成する dog1 = Dog("Max", "Bulldog") dog2 = Dog("Bella", "Poodle") print(dog1.display_info()) # 出力: Max is a Bulldog print(dog2.display_info()) # 出力: Bella is a Poodle |
出力:
|
1 2 3 4 |
Max is a Bulldog Bella is a Poodle |
ここで、dog1とdog2は別々のオブジェクトであり、それぞれ独自の属性を持ちます。
クラスのメソッドと継承
基本的なクラス構造に加えて、Pythonは継承をサポートします。継承を使うと、あるクラスが別のクラスの性質や振る舞いを引き継げます。この機能によりコードの再利用ができ、機能拡張も行いやすくなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 基底クラス Animal class Animal: def __init__(self, name): self.name = name def speak(self): return f"{self.name} makes a sound." # 派生クラス Dog は Animal を継承する class Dog(Animal): def speak(self): return f"{self.name} barks." # 派生クラス Cat は Animal を継承する class Cat(Animal): def speak(self): return f"{self.name} meows." # 派生クラスのオブジェクトを作成する dog = Dog("Rex") cat = Cat("Whiskers") print(dog.speak()) # 出力: Rex barks. print(cat.speak()) # 出力: Whiskers meows. |
出力:
|
1 2 3 4 |
Rex barks. Whiskers meows. |
この例では、DogとCatクラスがAnimalクラスを継承し、それぞれがspeak()メソッドを上書きして固有の振る舞いを実装します。
基本的な演算
算術演算
Pythonは算術計算を行うのに優れたツールです。組み込みの演算子を使って、加算、減算、乗算、除算を簡単に実行できます。基本的な算術演算を見てみます。
|
1 2 3 4 5 6 7 8 9 |
# 基本的な算術演算 addition = 5 + 3 # 8 subtraction = 10 - 4 # 6 multiplication = 7 * 3 # 21 division = 8 / 2 # 4.0 modulus = 9 % 4 # 1(割り算の余り) exponentiation = 2 ** 3 # 8(2の3乗) |
Pythonは一般的な演算の優先順位(PEMDAS:括弧、指数、乗算と除算、加算と減算)に従います。つまり、たとえば括弧で順序を変えない限り、加算よりも先に乗算が行われます。
比較演算子
比較演算子は値を比較し、真偽値(TrueまたはFalse)を返します。これは、コード内で意思決定をする必要があるときに非常に有用です。
|
1 2 3 4 5 6 7 8 9 |
# 比較演算子 is_equal = 5 == 5 # True is_not_equal = 5 != 3 # True is_greater = 7 > 4 # True is_less = 2 < 6 # True is_greater_equal = 4 >= 4 # True is_less_equal = 3 <= 5 # True |
これらの演算子は、条件に応じてプログラムの流れを制御するために、制御構造の中でよく使われます。
制御構造
条件分岐 - if
Pythonの条件分岐は、条件が真か偽かに基づいてコードを実行できます。最も基本的なのはif文です。
|
1 2 3 4 5 6 |
# 単純なif文 temperature = 75 if temperature > 70: print("It's a warm day!") # 条件がTrueなので出力される |
出力:
|
1 2 3 |
It's a warm day! |
条件分岐 - elif
elif(else if)やelseを使うと、複数条件を扱えます。
|
1 2 3 4 5 6 7 8 9 10 |
# if-elif-else文 temperature = 60 if temperature > 70: print("It's a warm day!") elif temperature > 50: print("It's a cool day!") # 条件がTrueなので出力される else: print("It's cold outside!") |
出力:
|
1 2 3 |
It's a cool day! |
ループ
ループは、同じ処理を複数回繰り返すために使います。Pythonにはwhileループとforループの2種類があります。
whileループ
whileループは、条件が真である限り処理を繰り返します。何回繰り返すかを事前に確定できない場合に便利です。
|
1 2 3 4 5 6 7 |
# whileループの例 count = 0 while count < 5: print("Count is:", count) count += 1 # 各反復でcountを1増やす |
出力:
|
1 2 3 4 5 6 7 |
Count is: 0 Count is: 1 Count is: 2 Count is: 3 Count is: 4 |
この例では、countが5未満でなくなるまでループが実行されます。
forループ
forループは、リスト、タプル、辞書、集合、文字列などのシーケンスを反復処理します。繰り返し回数が事前に分かる場合に特に有用です。
|
1 2 3 4 5 6 |
# forループの例 numbers = [1, 2, 3, 4, 5] for num in numbers: print("Number:", num) |
出力:
|
1 2 3 4 5 6 7 |
Number: 1 Number: 2 Number: 3 Number: 4 Number: 5 |
このループはnumbersリストの各要素を順に取り出して表示します。
ループと条件分岐の組み合わせ
ループと条件分岐を組み合わせると、より複雑な処理を実行できます。たとえば、数値のリストを走査し、ある条件を満たすものだけに処理を行うことができます。
|
1 2 3 4 5 6 7 |
# ループと条件分岐の組み合わせ numbers = [10, 15, 20, 25, 30] for num in numbers: if num > 20: print(num, "is greater than 20") |
出力:
|
1 2 3 4 |
25 is greater than 20 30 is greater than 20 |
このコードはリスト内の各数値をチェックし、20より大きい場合だけ表示します。
例:データのフィルタリング
年齢のリストがあり、ある閾値以上の要素だけを取り出したいとします。これは、分析前にデータを整形・変換する場面でよくある作業です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 年齢のリスト ages = [22, 35, 17, 40, 15, 27, 30] # 18以上の年齢を抽出する adult_ages = [] for age in ages: if age >= 18: adult_ages.append(age) print("Adults:", adult_ages) |
出力:
|
1 2 3 |
Adults: [22, 35, 40, 27, 30] |
この例では、18歳以上だけがadult_agesリストに追加され、最後に表示されます。
NumPyとPandasの導入
ここで示す例は、Pythonでデータを扱い分析するうえで、NumPyとPandasがどれほど強力かを示します。これらはデータサイエンティストにとって不可欠なスキルです。
NumPyによる配列の比較
NumPyはPythonで数値計算を行うための強力なライブラリです。NumPyの強みのひとつは、配列に対して要素ごとの演算を行える点にあります。たとえば、2つのグループの年齢を表す配列があり、それらを直接比較したい状況を考えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# numpyライブラリをインポートする import numpy as np # 2つのグループの年齢配列を作成する group_a = np.array([25, 32, 18, 40]) group_b = np.array([30, 28, 20, 35]) # group_aの年齢が30以上かどうかを比較する print(group_a >= 30) # group_aの年齢がgroup_bより小さいかどうかを比較する print(group_a < group_b) |
出力:
|
1 2 3 4 |
[False True False True] [ True False True False] |
この例では、group_a >= 30でgroup_aのうち30歳以上を判定し、group_a < group_bで対応する要素同士を比較します。
NumPyによるブール演算
個々の真偽値に対して論理演算を行えるのと同様に、NumPy配列に対しても論理演算を行えます。これは複数条件でデータを絞り込む際に特に有用です。たとえば、group_aの中で「20未満」または「35より大きい」人を見つけたいとします。
|
1 2 3 4 5 6 7 8 9 |
# logical_orを使って20未満または35より大きい年齢を見つける result = np.logical_or(group_a < 20, group_a > 35) print(result) # logical_andを使って20以上35以下の年齢を見つける result_and = np.logical_and(group_a >= 20, group_a <= 35) print(result_and) |
出力:
|
1 2 3 4 |
[False False True True] [ True True False False] |
ここでは、np.logical_orが「20未満または35より大きい」を満たす人を見つけ、np.logical_andが「20以上35以下」を満たす人を抽出します。
Pandasによるデータのフィルタリング
Pandasはデータ操作と分析のための強力なライブラリです。特に有用なのは、条件に基づいてデータを絞り込める点です。たとえば、顧客データのDataFrameがあり、購入回数が3回を超える顧客を見つけたいとします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# pandasライブラリをインポートする import pandas as pd # DataFrameを作成する data = {'customer_id': [1, 2, 3, 4, 5], 'purchases': [2, 5, 3, 1, 4]} customers = pd.DataFrame(data) # 購入回数が3回より多い顧客を抽出する loyal_customers = customers[customers['purchases'] > 3] # 抽出後のDataFrameを表示する print(loyal_customers) |
出力:
|
1 2 3 4 5 |
customer_id purchases 1 2 5 4 5 4 |
このコードは、customersから購入回数が3回を超える行だけを抽出します。
Pandasで複数条件を組み合わせる
Pandasでは論理演算子を使って複数条件を組み合わせられます。たとえば、購入回数が2回以上4回以下の顧客を見つけたい場合は次のようにします。
|
1 2 3 4 5 6 7 |
# 条件を組み合わせて購入回数が2回以上4回以下の顧客を抽出する selected_customers = customers[(customers['purchases'] >= 2) & (customers['purchases'] <= 4)] # 抽出後のDataFrameを表示する print(selected_customers) |
出力:
|
1 2 3 4 5 6 |
customer_id purchases 0 1 2 2 3 3 4 5 4 |
このコードは、Pandasで**&**を使って条件を結合し、購入回数が2〜4回の顧客を抽出します。
DataFrameの反復処理
場合によっては、DataFrameの各行を順に処理する必要があります。Pandasはiterrows()メソッドを提供しており、行ごとにループできます。
|
1 2 3 4 5 |
# DataFrameの行を反復処理する for index, row in customers.iterrows(): print(f"Customer {row['customer_id']} made {row['purchases']} purchases.") |
出力:
|
1 2 3 4 5 6 7 |
Customer 1 made 2 purchases. Customer 2 made 5 purchases. Customer 3 made 3 purchases. Customer 4 made 1 purchases. Customer 5 made 4 purchases. |
iterrows()を使うと、各行をSeriesとして取得し、必要に応じて処理できます。
条件に基づく新しい列の追加
Pandasでは、既存データに基づいて新しい列を簡単に作成できます。たとえば、購入回数に基づいて「ロイヤル顧客」かどうかを示す列を追加できます。
|
1 2 3 4 5 6 7 |
# 購入回数に基づいて新しい列'loyal'を追加する customers['loyal'] = customers['purchases'] > 3 # 更新後のDataFrameを表示する print(customers) |
出力:
|
1 2 3 4 5 6 7 8 |
customer_id purchases loyal 0 1 2 False 1 2 5 True 2 3 3 False 3 4 1 False 4 5 4 True |
このコードは、購入回数が3回より多い顧客に対してTrue、それ以外にFalseとなるloyal列を追加します。
apply()による効率的な列操作
DataFrameの行を反復処理する方法は便利ですが、データが大きい場合は効率が悪くなることがあります。Pandasのapply()メソッドを使うと、列全体に対してより効率的に処理を行えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# applyを使って購入回数に応じて顧客を分類する def categorize_customer(purchases): if purchases > 3: return 'High' elif purchases == 3: return 'Medium' else: return 'Low' customers['category'] = customers['purchases'].apply(categorize_customer) # 更新後のDataFrameを表示する print(customers) |
出力:
|
1 2 3 4 5 6 7 8 |
customer_id purchases category 0 1 2 Low 1 2 5 High 2 3 3 Medium 3 4 1 Low 4 5 4 High |
このコードでは、apply()を使って購入回数に応じて顧客を分類するcategory列を作成します。
まとめ
ここではまず邪馬台国データサイエンティストが使う言語ナンバー1のPythonの言語の基礎を紹介しました。この連載はまだまだ続きます。